
How to deal with AI Agents that Phone It In

December 10, 2025
Using Workflow Orchestrators to Prevent Planner Fatigue and Ensure Reliable Multi-Agent Execution
If you’ve worked with LLMs enough, you’re bound to have run into situations where they refuse to do what you’re asking, because it’s “too difficult”. As an example, see how your favorite LLM handles this prompt:
Rank every movie ever made and write a one-page review for each.Recently, while attempting to run security audits across a relatively small number of Drupal modules, I found that Claude Sonnet in Claude Code, the LLM I was using, would start slacking off compared to if I ran the prompt against only a single module.
To perform the code audits, I used two agents: I’d give an audit agent the path to a module, and have it perform a code security audit and write out a report. The second agent was a module discovery agent, which would search through the sites’ contrib and custom modules and then run the audit agent on any modules it found in those folders.
For the first few modules, the work was solid. But as it progressed, the LLM appeared to be shortcutting things and making guesses based on what it thought the module did. I ran it through 25 modules, and after 18 it announced: “there’s still 6 modules left, I'll batch those into the same audit.” As you might expect, that final audit did not meet my expectations. Running the audit agent on a single module produced far more comprehensive and useful output.

At first, I assumed Claude Code was intentionally throttling the workload; a hidden mechanism to discourage heavy tasks from flat-rate subscription users. It seemed plausible that the system might limit effort to protect resources from fixed-rate users. That assumption turned out to be wrong.
Planner Fatigue
What I was seeing wasn’t cost-based throttling, it turned out to be the model reprioritizing goals due to multiple, conflicting goals.
The discovery agent was told to loop through all contrib and custom modules and run the audit agent on each. So while the prompt is asking for an audit, at the meta-level, it's also asking Claude Code to complete the search, and while obvious, I don't care if the search ever completes or not, I know the audit will eventually complete, or worst case, fail partway through. But from the LLMs perspective, auditing a module is no more or less important than completing the find task. This leads to a conflict where the LLM decides to split the difference and slack off on the audits that are taking too long so that it can complete the overall task.
The LLM had what I think of as "planner fatigue." It attempted to satisfy multiple goals (finish the list and audit the code), and choose breadth over depth. The module discovery goal effectively caused the audit agent to get lazy.
Orchestration vs Agentic Planning (Borrowed from Microservices)
In software development the concepts of orchestration and choreography emerged from managing microservices. An orchestrator acts as a central brain, or controller to direct each service's actions and execution order. In choreography, the services act independently and react to their own events and coordinate through messaging, without requiring a central controller.
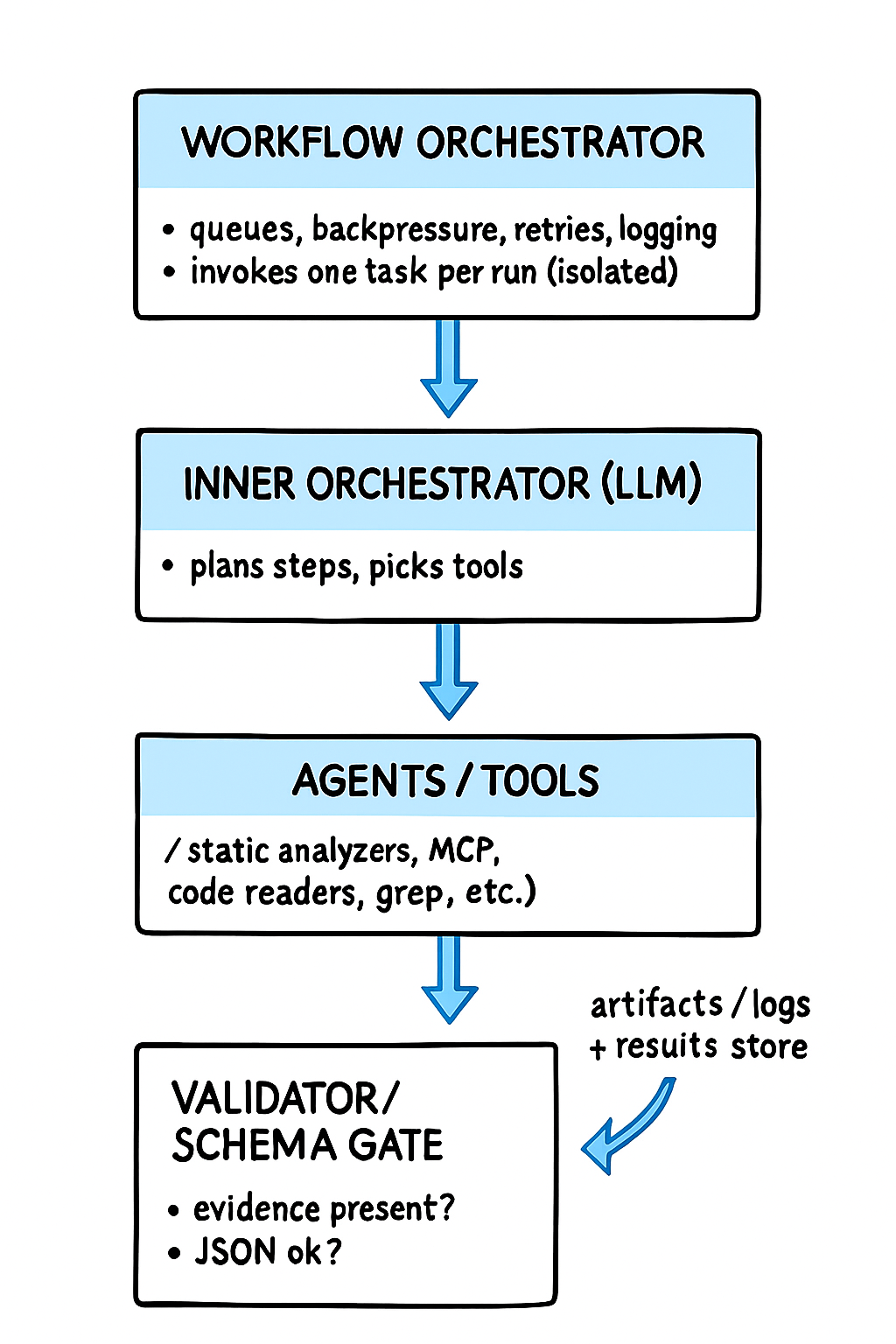
In AI systems we can see a similar divide, a workflow orchestrator invokes each agent as a discrete task with isolated context. An LLM-based orchestrator (or agentic planning) behaves more like the choreography within a conversation. The model maintains an internal context, and it may call sub-agents, MCP tools, and determine how to handle inputs on the fly.
When to Use Workflow Orchestration
In addition to batch or hybrid pipelines as described above, other situations where it will likely make more sense to use a deterministic orchestrator would be when you need:
- Repeatability (compliance or audits), especially if you need to ensure specific outputs exist. If a process fails to produce valid output then it can be flagged for debugging later.
- Durable long running processes that are resistant to network failures or other issues. You can handle these things and trigger re-runs in your orchestrator code.
- Hard limits on token usage or time limits. On very large tasks you may overload the system memory when jobs are being fed into the agents at a rate faster than they can be processed. For example, if you're pushing 100 tokens/second but your model is only handling around 20 tokens/second, it will keep accepting tasks even though it's constantly falling behind. Using backpressure in the orchestrator would prevent this.
- Zero cross-talk between processes. Each process needs to have its own isolated context independent of previous LLM runs. In my example above, it's possible that an audit of one module could be affected by the context of an audit on a previous module.
When to use LLM-driven orchestration
In the case where the next steps aren't fully known or understood, an agentic planning model will likely be preferred. Some good examples would be codebase analysis or any kind of research task. Tasks where the orchestrator needs to work with tools or choose which sub-agent to call, and most situations where you have a human in the problem solving loop.
This model will be much more adaptive and efficient than writing an if-else for every possible scenario.
Summary
In my original audit loop, I converted my module discovery agent to a very simple bash script that called my code audit agent manually on each one:
for module in modules/contrib/*; do
if [ -d "$module" ]; then
module_name=$(basename "$module")
claude -p --agent audit-module "$module" \
--allowedTools "Bash,Read" \
--permission-mode acceptEdits
fi
doneThe result was that each module had an equally comprehensive audit done by the LLM.
For any long running, multi-step process, the best option will almost certainly be a combination of both concepts. The outer loop should be a deterministic orchestrator that works with multiple LLM-based inner orchestrators as part of the process. Each inner orchestrator should operate on one unit of work, with strict input/output schemas and no memory of prior tasks.
All illustrations in this post were generated with ChatGPT using author-provided prompts.
Related Insights
-
/