
How Tag1 Reviews Code with AI: AI-PR-Review and Comprehensive-Review

June 17, 2026
At Tag1, we believe in proving AI within our own work before recommending it to clients. This post is part of our AI Applied content series, where team members share real stories of how they're using Artificial Intelligence and the insights and lessons they learn along the way. Here, Greg Chaix (Senior Infrastructure Engineer) walks through two open source AI code-review tools he built, one you run on demand and one that runs automatically in CI, and what a few months of using them on our own code has taught him.
Code review is where good engineering teams slow down. Not because reviewers are bad at it, but because a careful review takes real time, the kind of time that's hard to find when three other pull requests are waiting and someone is asking when the release goes out. So reviews get rushed, or they sit. Either way, the constraint is how much careful attention a team has to spend.
Over the past few months I built two tools to put AI into that gap. The first one runs in your terminal, on demand: you ask it for a review and it gives you one. It worked well enough that I wanted the same review available everywhere it mattered, not just on the code I happened to write with an AI assistant in the loop, and not just when an individual chose to run it. So I spawned a second tool from it and wired it into CI, so the review runs on every pull request as part of the pipeline. They share a lot of DNA and solve the same problem from opposite ends: one you reach for deliberately, one the process runs for you. We've been running both on some of our own code at Tag1, and that's the part I care about most. This isn't a demo. These are what review my work now.
Both are open source under Tag1's GitHub, and both are built to run on your own repositories:
- Comprehensive-Review: the on-demand Claude Code skill
- AI-PR-Review: the automatic CI reviewer
Comprehensive-Review: Review on Demand
Comprehensive-Review came first. It's a Claude Code skill you run by typing /comprehensive-review on a branch. There's no CI trigger and nothing automatic about it. You run it when you want it.
That deliberate invocation is the whole point. Because you're asking for it, it can do the heavier, slower work that wouldn't make sense on every single push. It launches a fleet of specialized agents in parallel, pulls their findings together into one ranked list instead of a pile of overlapping comments, and hands you back two things: a walkthrough of what the change actually does, plus a findings report sorted by how much you should care.
The most useful moment for it, at least for me, is before I open a pull request. I run it on my own branch, read what it found, address what it surfaces, and only then ask a human to look. A careful reviewer's attention is the scarce resource, and I'd rather spend it on the questions that actually need a human than on the issues a tool could have caught for me first.
It builds on top of the existing Anthropic pr-review-toolkit plugin agents rather than reinventing them, and adds the higher-level analysis those don't cover: security review, architecture and coupling analysis, and mechanical boundary-condition tracing. It also handles all the remote git plumbing, so it can post its findings as an inline review on a pull request (including someone else's) if that's what you want.
AI-PR-Review: Review in the Pipeline
The Comprehensive-Review skill does its job well, and I lean on it heavily: my own setup requires running it before I open a pull request or cut a release. But that discipline only reaches code I write with Claude Code in the loop. Plenty of code isn't: contributions from people who don't use the skill or repositories where the review should happen regardless of who pushed or what tools they used. For that, a personal habit isn't enough; the review has to be part of the pipeline. AI-PR-Review is that: the same review approach Comprehensive-Review brought to my own workflow, turned into a CI action. It's reproducible, consistent, and enforced by the process rather than by anyone remembering. You drop a workflow file into a repository, add an API key, and from then on every pull request gets reviewed the moment it's pushed. It posts a summary comment on the first push and then leaves inline findings on the exact lines that need attention, the same way a human reviewer would.
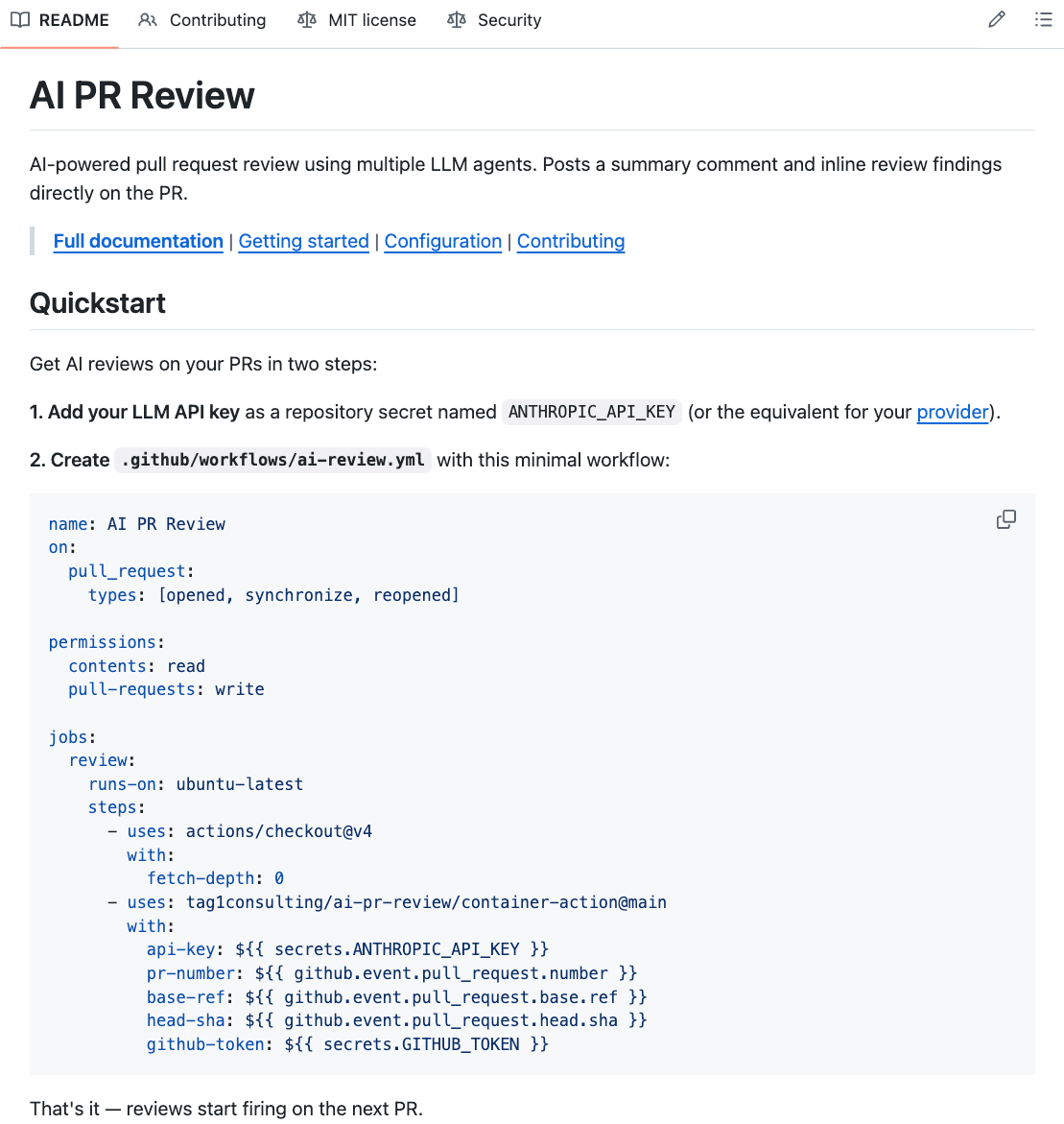
The same cast of reviewer agents carried over from the skill, reimplemented for a CI context rather than copied wholesale, because that was the point: the review you get on a pull request should be the review you'd have run by hand. AI-PR-Review computes the diff, figures out which languages changed, and runs those agents, each looking at the change from a different angle. In the "quick" mode it provides a bug-and-logic reviewer and a reviewer that hunts for swallowed errors and unsafe fallbacks. In its fuller mode, it provides a security reviewer, an architecture reviewer, an edge-case tracer that walks every branch, and a "fresh eyes" reviewer that's given zero project context on purpose, since familiarity is how real bugs slip past people who know the codebase too well.
Alongside the AI agents, it runs the deterministic checks too. That includes secret scanning, dependency CVE lookups, SAST, plus the right linter for whatever changed, no matter the language the code is written in. The two halves catch different things. The scanners are deterministic: they flag the patterns they're built to flag, every time, with no opinion attached. The AI agents are good at the fuzzier work a fixed rule can't express, like spotting that an error is being swallowed, that a change doesn't match how the rest of the file behaves, or that an edge case isn't handled. Neither half replaces the other, so the tool runs both.
The CI action works on GitHub, GitLab, and Bitbucket, and it speaks to Anthropic, OpenAI, Google, or a Bedrock proxy, so you're not locked into one model vendor. We run it on Anthropic's models day to day for two reasons: our internal AI usage policy routes through an Anthropic account covered under our data agreement, and Anthropic's models produced more detailed reviews in our benchmarks. OpenAI came out somewhat cheaper at comparable quality, the kind of tradeoff you only learn by measuring it on your own diffs.
What Running Them in Production Actually Taught Me
Lesson 1: The Tools Catch Real Problems in Their Own Pull Requests
I wired it into its own CI early on, which means every change I make to the reviewer gets reviewed by the version already running. It earned its keep by flagging an expression-injection hole in its own GitHub Actions workflows. Values like $ and $ were being interpolated directly into run: blocks, which is a classic shell-injection vector: GitHub expands the expression into the script body before bash ever sees it, so a crafted branch name or input can break out into arbitrary commands. The fix was to route those inputs through environment variables so the shell never interpolates them, and while I was in there, to mask the github-token in logs too, since a caller might pass a PAT or fine-grained token that GitHub doesn't auto-redact. None of that is exotic.
It's exactly the kind of finding a careful human reviewer would catch on a good day, which is the point.
The uncomfortable part is the corollary: the tool slows your merges down by being right, and you have to make your peace with that. A reviewer that never blocks you isn't reviewing.
Lesson 2: False Positives Are a Design Problem, Not an Annoyance
The sharpest example I hit was version hallucination. The models have a training cutoff, so when a pull request bumped a dependency to a release newer than the model had ever seen, the reviewer confidently flagged it as "unreleased" and raised a High-severity finding, which tripped a request-for-changes on a perfectly valid pull request. You can't prompt your way out of that entirely, because the model genuinely doesn't know. So the fix was two-layered. First, a hard constraint in the reviewer prompts spelling out the narrow circumstances under which a version finding is even allowed: malformed syntax, an explicit downgrade, a cited CVE, or a missing pin, and nothing else. Second, and more interesting, a verification gate: a suppression rule can mark a finding as needing confirmation against an authoritative source, so a "this version doesn't exist" finding only survives if the language's own package registry agrees the release is actually missing. The model flags the version; the language's package registry decides whether it's actually missing.
The same principle (distrust the raw output, do work to earn the reader's attention) runs through a lot of the plumbing you'd never see in a feature list. A confidence floor drops sub-threshold noise before it can even trigger an expensive verification call, and near-duplicate findings get clustered so a single issue doesn't get reported five times. And when a finding is a genuine false positive, you need to be able to say so and have it stick. Every finding carries a stable, fingerprint-based ID, rendered as [F1], [F2], and so on, that survives across review cycles, so you can comment /ai-pr-review dismiss F1 and have that finding stay gone on the next push. Once every open thread and flagged finding is resolved, the tool withdraws its own request-for-changes. If the tool is wrong often enough, people stop reading it, and a review nobody reads is worth nothing. The credibility of the review is the product.
Lesson 3: Harm Reduction Has to Come First
If the last lesson was about what a reviewer says, this one is about what it values, and it's the lesson I'd most want another engineer to take away. Early on I treated the agents as a collection of detectors: add a security reviewer, add an edge-case tracer, add an architecture pass, and quality goes up. It does, to a point. But a detector tuned the wrong way just generates more noise, and past a certain number of agents the noise became the problem. What moved the needle was not another agent. It was holding all of them to the same set of rules, and putting one rule above the others.
So I wrote a shared governance block, a single set of instructions injected into the prompt of every finding-producing agent, right after its role-specific instructions, derived from the same operating rules I hold myself to when I let an AI touch real work. It's always on; there's no flag to disable it. It carries a few rules, but one matters far more than the rest: harm reduction comes first.
That principle is not original to me. My own operating rules for AI work are built directly on Asimov's Laws of Robotics. I hardcode the First Law (an AI must not harm a human, or through inaction allow harm) and the Second Law (it must obey human instructions except where they conflict with the First), and I deliberately countermand the Third Law: where Asimov's robots protect their own existence, mine are told never to pursue self-preservation. The First Law sits above everything. That ordering is the whole point, and it carries straight into how the reviewer rates what it finds.
In practice that means severity is measured by harm, not by aesthetics. Instead of letting each agent invent its own scale, every finding is rated by one question: what concretely goes wrong if this ships? Exposing user or third-party data, breaking a shared system like CI or a deployment, losing data, leaking credentials: those are Critical or High. A maintainability nitpick or a defense-in-depth gap with no realistic path to harm is Medium or Low, however subtle the issue was to detect. The rule cuts both ways and says so explicitly: don't inflate severity for a stylistic disagreement, and don't deflate it for something small that genuinely hurts.
Severity is the most important signal a reviewer emits, because it decides whether a human stops what they are doing. If a tool marks everything urgent, people learn to ignore it; if it buries the one finding that would actually have hurt someone under a pile of style nitpicks, the harm ships anyway. Either failure defeats the entire purpose of having the review. Anchoring the whole report to "what is the real-world harm here" is what keeps it honest, and it is the rule I would fight hardest to keep if I could keep only one.
There are other rules in the block, and they earn their place: don't reinvent code that already exists in the diff, never name a flag or function or file the agent can't actually point to in the change it was given, redact anything secret-shaped before it lands in a public comment. They reduce noise and prevent the reviewer from wasting a maintainer's time. But they are housekeeping next to the first rule.
An AI reviewer that's confidently wrong is worse than no reviewer at all, because it costs a human the time to disprove it and quietly teaches that human to stop reading.
A reviewer that gets severity wrong is worse still, because the cost there is not wasted time, it's the harm that shipped while everyone was looking at something else. Most of the lasting quality work on these tools went into avoiding both, and most of all into never letting a real harm slip through while the report looked busy elsewhere.
Try Them
Both are open source; Comprehensive-Review came first. Both are built to run on your own repositories:
- Comprehensive-Review: the on-demand Claude Code skill
- AI-PR-Review: the automatic CI reviewer
If you run them on your own code and they catch something, I'd genuinely like to hear about it. And if they cry wolf, I want to hear about that even more.
Related Insights
-
/